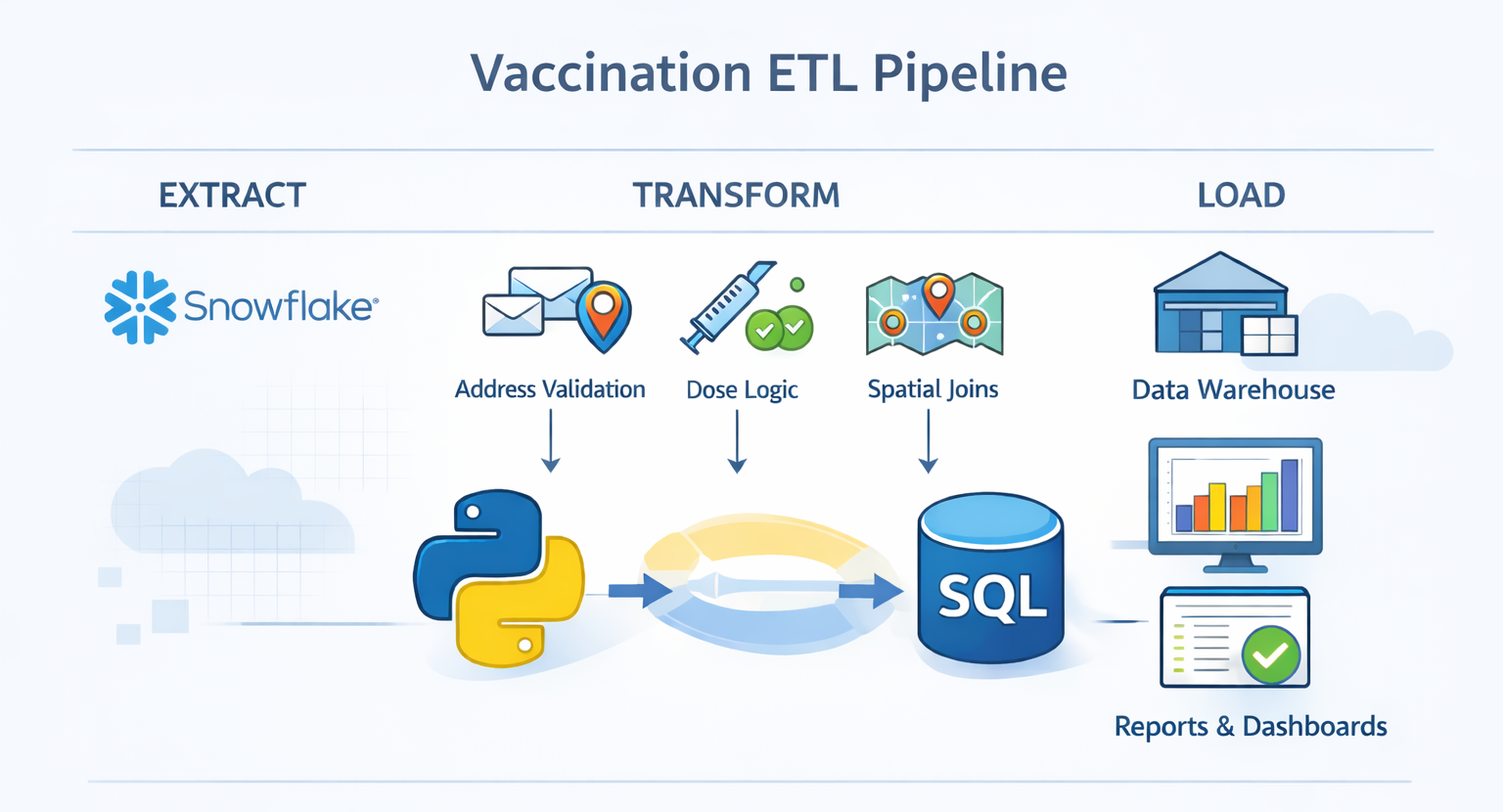
Vaccination data pipeline
While working for Los Angeles County, I designed, built, and maintained an end-to-end ETL pipeline to process millions of vaccination records on a daily basis for use across multiple downstream teams. The system used Python and SQL to ingest raw data from the state database, hosted in Snowflake, and performed numerous steps, principally: validation and geocoding of physically address, logic for evaluating the validity of doses based on epidemiological criteria, combining these data to produce standardized table outputs. I implemented automated validation, error handling, and monitoring to ensure reliability and auditability. The pipeline reduced manual data handling, improved data consistency, and enabled other teams to work from a single point of truth.
Data this pipeline generated can be found on the respiratory vaccine dashboard for LA County.
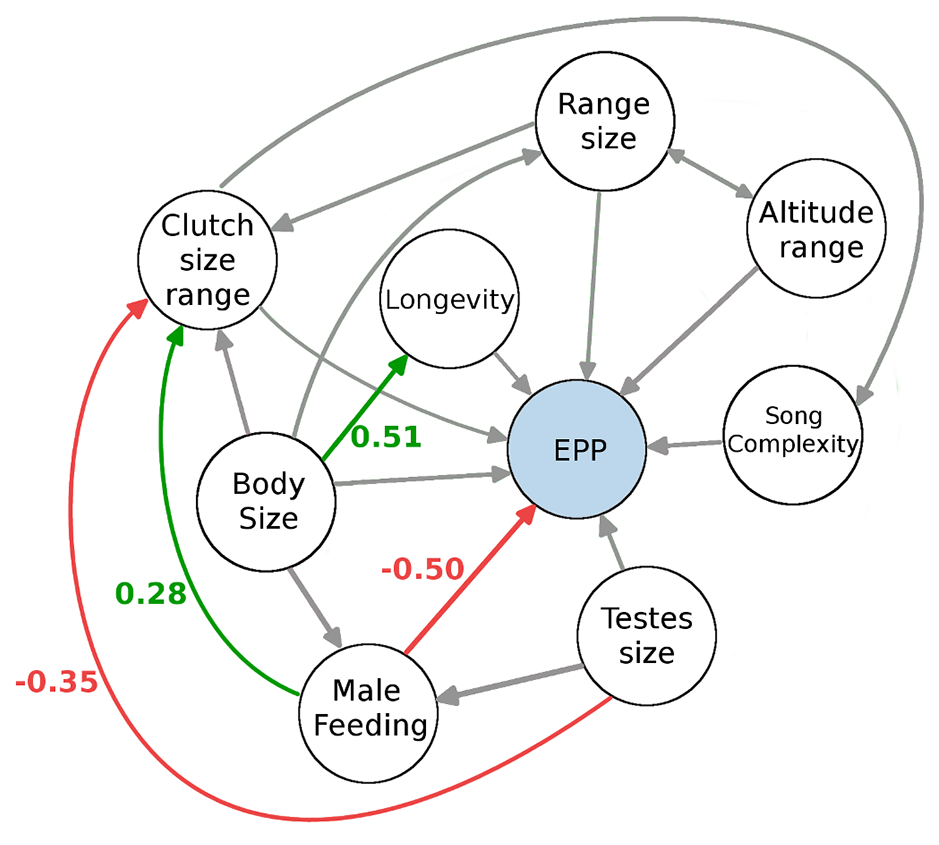
Path analyses to disentangle complex systems
Biological systems are notoriously messy — there are likely multiple potential predictive factors which may also co-vary with each other. I employed structural equation modelling (a type of path analysis) to allow the definition of multiple potential pathways across the network to asses their impact on the variable of interest, as well as each other. I tested how different number of connections in the network, and different treatments of the statistical non-independent of data points, may influence the outcome. These results were presented and published in scientific literature, and presented at scientific conferences.
A full list of academic publications can be found on Google Scholar.
More examples of projects can be found on my GitHub page